
티스토리 뷰
1. 뉴럴 네트워크 도식화
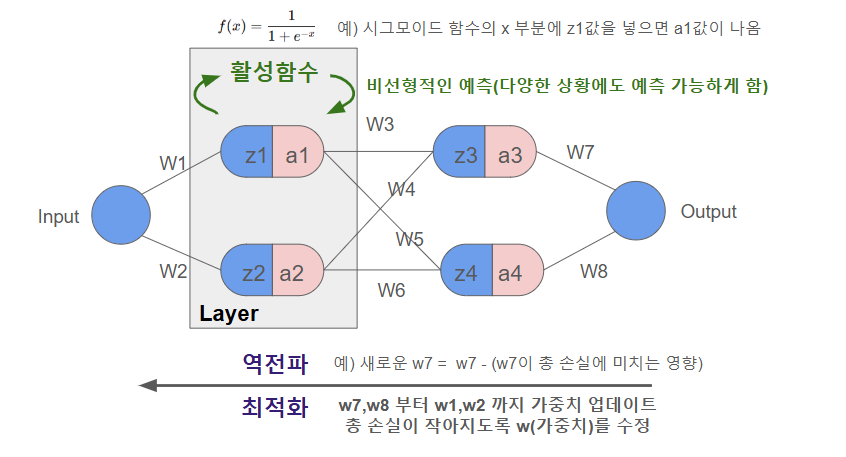
2. 활성화 함수 (Optimization Algorithm)
- Activation Function, 신경망에서 입력값을 처리해 출력값을 변환하는 수학적 함수
- 모델이 복잡한 문제를 해결할 수 있도록 데이터를 비선형적으로 변환한다(예: 직선이 아닌 곡선 모양으로 예측가능)
- 활성화 함수가 없으면 layer가 있는 의미가 없기 때문에 중요하다
| 활성화함수 | Sigmoid | Softmax | Tanh | ReLU | Leaky ReLU |
| 공식 |  |
 |
 |
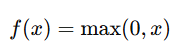 |
 |
| 출력범위 | 0 ~ 1 | 0 ~ 1 | -1 ~ 1 | 0 ~ 무한대 | - 무한대~ 무한대 |
| 용도 | 출력층(이진분류) | 출력층(다중분류) | 은닉층(양수/음수) | 은닉층(양수) | ReLU 대안(양/음) *α:작은양수(0.01) |
3. 최적화 알고리즘
- 손실함수를 최소화 하기 위해 손실 함수의 기울기를 계산하고 가중치와 편향을 조정하는 방법
| 알고리즘 | 경사하강법 | 모멘텀 | RMSProp | Adam |
| 공식 | 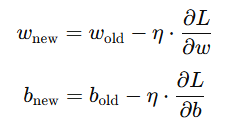 : 학습률 |
 관성 계수(보통 0.9) |
 : 기울기의 제곱 이동 평균 : 작은 값(분모 0 방지) |
 : 1차 모멘텀(평균 기울기) : 2차 모멘텀(기울기 제곱 평균) |
| 특징 | 1)SGD 확률적 경사하강법 (랜덤) 2)미니배치 경사하강법 (미니배치) |
기울기의 변화량을 누적하여 빠르게 학습 | 최근의 기울기 변화를 더 많이 반영 | 모멘텀 + RMSprop |
4. 손실함수
- 실제값과 예측값의 차이인 오차를 여러 방식으로 수치화 한 것
| 손실함수 | MAE 평균절댓값오차 |
MSE 평균제곱오차 |
교차 엔트로피 | KL발산 |
| 공식 |  |
 |
 |
 |
| 용도 | 음수와 양수가 상쇄되는걸 방지하고 싶을때 | 큰 오차에 더 큰 패널티를 주고 싶을때 | 로그를 사용해 확률 (0~1)로 해석 |
확률분포를 비교할때 (생성모델/강화학습) |
※ 참고자료 : 코딩애플(Tensorflow 딥러닝 기초부터 AI실무까지) https://codingapple.com/course/python-deep-learning/
반응형
'AI > 딥러닝' 카테고리의 다른 글
| [딥러닝] 공유 받은 구글 드라이브 알집 파일 colab에서 내 구글드라이브로 저장시키고 알집풀기 (0) | 2024.12.03 |
|---|---|
| [딥러닝] 언제 딥러닝이 필요할까? (1) | 2024.11.29 |
| [딥러닝] 신경망 모델 비교, Tensorflow 예시 (3) | 2024.11.28 |
| [딥러닝] Tensorflow(Keras) 기본 문법 (0) | 2024.11.19 |
| [딥러닝] 신경망 Neural Network (0) | 2024.11.19 |
공지사항
최근에 올라온 글
최근에 달린 댓글
- Total
- Today
- Yesterday
링크
TAG
- 티스토리챌린지
- C언어
- 영어회화
- 뉴스
- opic
- 기초
- 다이어트
- 습관
- 고득점 Kit
- 빅데이터 분석기사
- 스크랩
- 경제
- 아침운동
- SQL
- 오블완
- Python
- 오픽
- 실기
- 아침
- IH
- llm
- ChatGPT
- 루틴
- 미라클모닝
- 30분
- 프로그래머스
- Ai
- 운동
- 갓생
- 줄넘기
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
글 보관함