
티스토리 뷰
1. 신경망
- Neural Network, 생물학적 뉴런의 동작을 모방하여 데이터 간의 관계를 학습
- 뉴런의 기본 동작
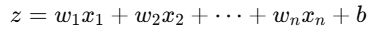
- z를 활성화 함수에 전달하여 뉴런이 활성화될지 여부를 결정
1) 입력층(Input Layer)
- 입력 데이터를 받아들이는 계층, 각 특징(feature)이 뉴런 하나에 대응
- 이미지 데이터 64*64 크기의 입력층 뉴런 갯수 = 64*64
- 활성화 함수는 사용하지 않는다
2) 은닉층(Hidden Layers)
- 입력 데이터를 처리하고, 패턴이나 특징을 학습
- 은닉층의 갯수와 뉴련 수는 문제의 복잡도에 따라 결정된다.
- 하나 이상의 은닉층을 포함하며, 층이 많아질수록 딥러닝이 된다.
- 활성화 함수 사용하여 복잡한 패턴을 학습: tanh, ReLU
- 과적합 방지를 위해 규제(Regularization) 사용
3) 출력층(Output Layer)
- 최종 예측값을 출력하는 계층
- 활성화함수: sigmoid(이진 분류), softmax(다중 분류)
- 회귀 문제의 경우 활성화 함수없이 그대로 출력한다.
- 출력 뉴런의 개수는 예측해야 할 클래스 또는 값의 수에 따라 결정(이진분류:1, 다중분류: 클래스 수)
2. 신경망의 데이터 흐름
1) 순전파: 입력층 → 은닉층 → 출력층
- 각 층에서 가중치와 편향, 활성화 함수를 통해 데이터를 처리
2) 손실 계산(loss)
- 출력층에서 예측값과 실제 값의 차이를 기반으로 손실을 계산
3) 역전파: 손실을 기준으로 가중치와 편향을 업데이트 하기 위해 기울기를 계산
- 경사하강법을 사용하여 가중치를 조정
3. 신경망의 가중치와 편향
1) 가중치: 각 연결에서 입력 데이터의 중요도, 학습 과정에서 최적화됨
2) 편향: 뉴런의 활성화 기준점을 조정
- 입력이 모두 0이어도 뉴런이 활성화될 수 있도록 도움(z=b) => 모델이 더 많은 패턴을 학습할 수 있음
4. 신경망의 활성화 함수
- Activation Function: 뉴런이 어떤 신호를 전달할지 결정하는 스위치 역할
1) tanh(은닉층): 예측값을 -1과 1사이로 출력, ReLU 이전의 은닉층에서 많이 사용, 출력값의 범위가 음수와 양수 모두 필요한 경우
- 중립적인 상태까지 표현 (-1,0,1), 대칭적이라 더 유연한 결정 가능
- (e^x) ,(e^-x) 계산 필요
2) relu(은닉층): 예측값을 양수면 그대로, 음수면0으로 출력, 이미지처리(CNN), 자연어처리(NLP)등 가장 널리 사용
- 전달해야 할 신호를 거르고, 강하게 만듦. (필요 없는)음수 신호는 차단, (필요한)양수 신호는 전달
- 간단한 비교연산(max)으로 sigmoid나 tanh에 비해 훨씬 빠르게 계산 가능
- sigmoid와 tanh은 출력값이 특정 범위에 수렴하기 때문에 역전파시 기울기가 0에 가까워져 학습이 멈출 수 있다
- ReLU는 양수 구간에서 기울기 값이 항상 1이므로, 역전파 과정에서 기울기 소실 문제가 완화된다.
- 입력이 음수일때 뉴런이 죽는 문제를 해결하기 위해 Leaky ReLU(음수 입력도 작은 기울기를 갖도록 수정)들이 개발됨
3) sigmoid(출력층): 예측값을 0과 1사이로 출력, 이진분류에서 예측값을 확률 값으로 반환
- 작동 여부를 결정, 0에 가까우면 꺼짐, 1에 가까우면 켜짐
- (e^-x) 계산 필요
4) softmax(출력층): 각 클래스 별 0과 1사이 값으로 출력, 총합이 1 , 다중 클래스 분류에서 사용
- 선택을 확률로 변환, 메뉴 중 가장 먹고싶은 음식을 고를때 각 음식의 선호도를 계산
5. 규제(Regularization)
- 과적합 방지를 위해 모델 복잡도를 제한하여 일반화 성능(Generalization)을 향상시키는 것
1) L1(Lasso), L2(Ridge) 정규화
- L1: 가중치의 절대값 합
- L2: 가중치의 제곱합
2) 드롭아웃
- 뉴런의 출력층을 무작위로 비활성화(0으로 설정)하여 다양한 뉴런 조합을 학습하게 함
from tensorflow.keras.layers import Dropout
model.add(Dropout(0.5)) # 드롭아웃 확률 50%
3) 데이터 증강 (Data Augmentation)
- 모델이 다양한 상황에서 일반화할 수 있도록, 데이터를 변형
- 이미지 데이터(회전, 크기 조정, 색상 변화 등), 텍스트(동의어 치환, 문장 순서 변경 등)
from tensorflow.keras.preprocessing.image import ImageDataGenerator
datagen = ImageDataGenerator(
rotation_range=20,
width_shift_range=0.2,
height_shift_range=0.2,
horizontal_flip=True
)
4) 조기 종료(Early Stopping)
- 검증 데이터 성능(손실값)이 향상되지 않을때 학습을 중단(과적합이 발생하기 전에 훈련 종료)
from tensorflow.keras.callbacks import EarlyStopping
early_stopping = EarlyStopping(monitor='val_loss', patience=5, restore_best_weights=True)
model.fit(X_train, y_train, validation_data=(X_val, y_val), callbacks=[early_stopping])
5) 배치 정규화
- 각 층의 입력값을 정규화(각 배치마다 평균과 표준편차를 계산하고 스케일, 이동)하여 학습을 완정화
- 기울기 폭발/ 손실을 완화하고, 학습 속도를 높이기 위해서
from tensorflow.keras.layers import BatchNormalization
model.add(BatchNormalization())
'AI > 딥러닝' 카테고리의 다른 글
| [딥러닝] 언제 딥러닝이 필요할까? (1) | 2024.11.29 |
|---|---|
| [딥러닝] 신경망 도식화, 가중치, 활성함수, 경사하강법, 역전파 알고리즘 (1) | 2024.11.28 |
| [딥러닝] 신경망 모델 비교, Tensorflow 예시 (3) | 2024.11.28 |
| [딥러닝] Tensorflow(Keras) 기본 문법 (0) | 2024.11.19 |
| [딥러닝] 1.데이터셋준비 - kaggle 파일 colab에서 다운, 압축해제 (0) | 2024.11.18 |
- Total
- Today
- Yesterday
- 갓생
- IH
- 줄넘기
- 30분
- Ai
- 영어회화
- 실기
- ChatGPT
- 아침운동
- 경제
- 아침
- 스크랩
- 뉴스
- 고득점 Kit
- SQL
- 오블완
- llm
- C언어
- 오픽
- 프로그래머스
- 루틴
- 기초
- 미라클모닝
- 티스토리챌린지
- 빅데이터 분석기사
- 습관
- 다이어트
- 운동
- opic
- Python
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |