
티스토리 뷰
Q. 엔트로피(Entropy)와 Information Gain에 대해 설명해주세요.
1. 엔트로피란?
- 주로 의사결정 트리나, 데이터 분석 시 데이터셋이 얼마나 정돈되어있는지, 혼란스러운지 데이터의 불확실성을 측정할 때 사용
- 데이터의 불확실성을 측정하는 척도
- 엔트로피가 0 : 완전 확실 → 완벽하게 분류된 상태 (모델의 분류가 명확)
- 엔트로피가 항상 낮은 상태를 목표로 하면 과적합의 문제가 발생할 수 있다.
- 확률이 균등하게 분포된다 → 엔트로피가 높다

2. 정보이득이란?
- 주로 의사결정 트리, 랜덤 포레스트에서 사용됨
- 특정 속성을 기준으로 데이터를 분할 했을 때 엔트로피가 얼마나 감소했는지를 측정
- 분할 후 분류가 명확할수록(엔트로피가 감소할 수록) 정보 이득이 크다
- 의사결정 트리에서 분할 기준을 선택할 때, 정보 이득이 큰 기준을 선택해 트리를 생성한다.
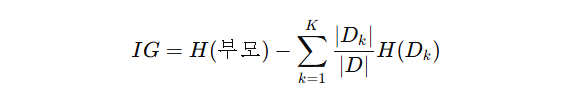
3. 크로스 엔트로피(Cross Entropy)
- 주로 딥러닝 모델의 다중 클래스 분류 문제에 사용된다 (로지스틱 회귀, 딥러닝(softmax, NLP))
- cross: 두 분포를 교차(cross)해서 비교하는 방식
- 모델이 예측한 확률 분포와 실제 데이터 분포 사이의 차이를 측정
- 실제 값이 p=[1,0](클래스 1이 정답) 인데, 예측 값이 q=[0.9,0.1]인 경우, H = -(1*log0.9+0*log0.1)
- p=q일때, 즉 예측이 완벽하면 손실이 0(최솟값), 예측이 실제값에서 멀어질수록 손실이 증가한다.
- 엔트로피는 p만, 크로스 엔트로피는 p랑 q랑 비교!!

'AI > 기술면접준비' 카테고리의 다른 글
| [기술면접] 정규화(Regularization), Lasso(L1 규제), Ridge(L2 규제) (0) | 2024.12.14 |
|---|---|
| [기술면접] 오차(Error)와 편향(Bias), 분산(Variance), 정규화(Regularization) (0) | 2024.12.13 |
| [기술면접] 중심극한정리는 왜 유용한걸까요? (0) | 2024.12.02 |
| [기술면접] 정규성(Normality) 검정 (2) | 2024.11.14 |
| [기술면접] 정규화(Normalization) (0) | 2024.11.13 |
- Total
- Today
- Yesterday
- SQL
- 고득점 Kit
- 실기
- 스크랩
- C언어
- 경제
- 빅데이터 분석기사
- 기초
- 운동
- 프로그래머스
- 영어회화
- 아침
- opic
- Ai
- 미라클모닝
- 뉴스
- 오블완
- IH
- Python
- 루틴
- 오픽
- 습관
- ChatGPT
- 줄넘기
- 티스토리챌린지
- llm
- 다이어트
- 갓생
- 아침운동
- 30분
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |