
티스토리 뷰
1. 크롤링이란?
- 웹에서 정보를 수집하는 기술
- 쇼핑몰의 가격 정보를 크롤링하여 경쟁사 분석, 뉴스 기사나 학술 정보를 크롤링하여 데이터 분석 등에 사용
2. 사용법
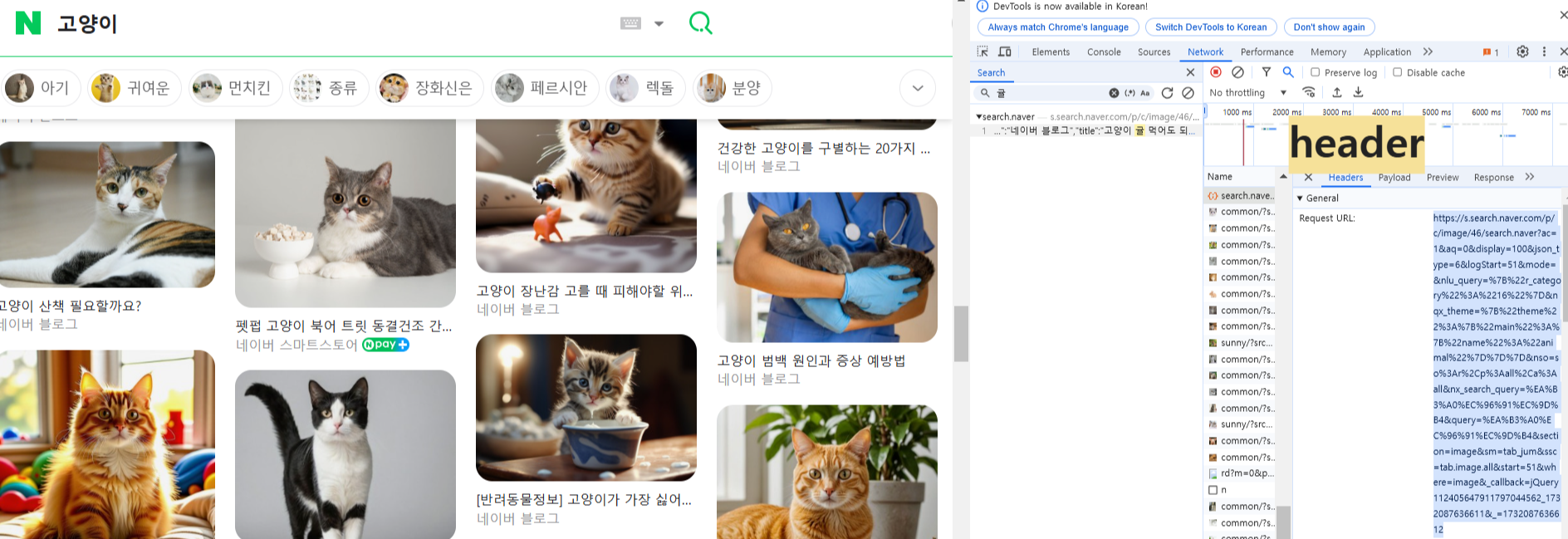
- 무한 스크롤의 경우 구글 크롬 검사(개발자모드) > Network 탭을 열고, 스크롤을 내린뒤 나오는 글 중 특정 글자를 filter에서 검색하고 클릭한다. 그 다음 header 탭을 클릭하면 Request URL:에 URL주소를 알려준다. 해당 url로 get요청을 하면 selenium으로 스크롤을 내리거나 할 필요 없이 json이나 beautifulsoup로도 간단하게 크롤링을 할 수 있다.
1) 데이터가 json 형식으로 생긴 경우
import requests
import json
page = requests.get("크롤링 하고 싶은 웹페이지 주소")
data = json.loads(page.content)
# 딕셔너리 형태로 저장됨2) 데이터가 html 형식으로 생긴 경우
import requests
from bs4 import BeautifulSoup
page = requests.get("크롤링 하고 싶은 웹페이지 주소")
soup = BeautifulSoup(page.content,'html.parser')
# myclass라는 클래스에 있는 글자를 가져오고 싶을때
data = soup.select('.myclass')[0].text
# yourclass라는 클래스에 있는 p태그에 있는 글자를 가져오고 싶을때
data = soup.select('.yourclass p')[0].text
# ourclass라는 클래스 안에 있는 theirclass에 있는 글자를 가져오고 싶을떄
data = soup.select('.ourclass .theirclass')[0].text- 클래스는 .클래스명
- id는 #아이디명
- 태그는 아무것도 안붙이고 그냥 태그명 입력
3) 이미지 저장
import os
import urllib.request
# 이미지 저장 폴더 생성
output_dir = "img"
os.makedirs(output_dir, exist_ok=True)
img_url = "이미지 다운받을 수 있는 링크"
try:
# 파일 저장 경로
file_path = os.path.join(output_dir, '저장하고 싶은 파일명.jpg')
# 이미지 다운로드 및 저장
urllib.request.urlretrieve(img_url, file_path)
print(f"이미지 저장 성공: {file_path}")
except Exception as e:
print(f"이미지 저장 실패 (URL: {img_url}) - {e}")
3. 데이터 프레임으로 저장
- 데이터를 쉽게 정리하고, SQL과 연결하기 위해서 데이터 프레임으로 변경하고, csv로도 저장해보자
import pandas as pd
df = pd.json_normalize(json_data)[['json 자료 중 사용하고 key 이름들(컬럼명으로 변경됨)']]
df
df.to_csv('my_db.csv',index=False)
db_df = pd.read_csv('my_db.csv')
db_df반응형
'AI > AI 서비스 개발' 카테고리의 다른 글
| [AI 서비스 개발] 삼성노트북 블루투스 사라짐, 윈도우 재부팅 (1) | 2024.11.24 |
|---|---|
| [AI 서비스 개발] python과 mysql 연동하기(비밀번호 특수문자 주의) (1) | 2024.11.21 |
| [AI 서비스 개발] LLM 활용 사례 (1) | 2024.11.15 |
| [AI 서비스 개발] 린스타트업과 MVP (2) | 2024.11.15 |
| [AI 서비스 개발] LLM + RAG (2) | 2024.11.15 |
공지사항
최근에 올라온 글
최근에 달린 댓글
- Total
- Today
- Yesterday
링크
TAG
- 오블완
- opic
- 프로그래머스
- C언어
- 미라클모닝
- 영어회화
- 스크랩
- 줄넘기
- 30분
- 루틴
- llm
- 아침
- 고득점 Kit
- Ai
- 갓생
- Python
- 기초
- 티스토리챌린지
- SQL
- 아침운동
- 운동
- 뉴스
- 다이어트
- 습관
- IH
- 경제
- 빅데이터 분석기사
- ChatGPT
- 실기
- 오픽
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
글 보관함